- MySitemapGenerator
- Раздел помощи
- Создание XML карт сайта
Создание XML карт сайта
Поддерживаются следующие типы документов:
- Обработка и индексация: HTML (основной робот), WAP WML/xHTML (мобильный робот)
- Обработка: Adobe PDF, Microsoft office DOC/DOCX, RTF, TXT.
Для того чтобы значение даты и времени документов в Sitemap соответствовало фактическому значению, возвращаемому Вашим сервером (Last-Modified), в опции формирования lastmod выберите параметр «по времени ответа сервера».
Наш робот обрабатывает три допустимых в HTTP-протоколе формата для представления метки времени и даты: RFC-822, RFC-850 и ANSI.
Обратите внимание на то, что робот не производит проверку и/или актуализацию даты в ответе Вашего сервера, используя ее так, как она была возвращена.
Генератор позволяет собрать и добавить в создаваемый файл Sitemap информацию об изображениях, расположенных на страницах Вашего сайта. Для URL-секции каждой страницы, на которой будут обнаружены изображения, будет добавлена соответствующая информация, согласно протоколу Google Sitemap-Image.
Следующий пример показывает фрагмент записи в файле Sitemap для URL http://website.tld/sample.html, на котором имеется два изображения:
<url>
<loc>http://website.tld/sample.html</loc>
<image:image>
<image:loc>http://website.tld/logo.jpg</image:loc>
</image:image>
<image:image>
<image:loc>http://website.tld/photo.jpg</image:loc>
</image:image>
</url>
Mysitemapgenerator может обнаружить обозначенные локализованные версии страниц Вашего сайта на других языках и/или предназначенные для определенных стран.
Наш робот обрабатывает инструкции в HTML-коде, а так же HTTP-заголовки.
Пример указания альтернативной версии веб-страницы в HTML-коде (помещается в раздел <head> веб-страницы):
<link rel="alternate" href="http://www.website.tld/alternate_page.html" hreflang="en-GB" />
Link: <http://www.website.tld/alternate_page.html>; rel="alternate"; hreflang="en-GB"
Значение атрибута hreflang должно содержать код языка в формате ISO 639-1 и, при необходимости, код страны в формате ISO 3166-1 Alpha 2 альтернативного URL.
В отличие от бесплатной версии, где проверка доступности ссылок завершается одновременно с окончанием процесса индексации (до нахождения 500 URL), в платной версии генератора проверка продолжается до последней ссылки, даже если индексация завершена. Это гарантирует, что в Sitemap не попадут битые ссылки или редиректы.
Хотя это не противоречит протоколу Sitemaps и не является ошибкой, возможное наличие ссылок, например, на редирект может вызвать соответствующее замечание Google Webmaster Tools о наличии не прямых ссылок в карте сайта.
По умолчанию большой Сайтмап разбивается в соответствии с требованиями протокола XML Sitemaps и поисковых систем – Вы получите несколько файлов, не более чем по 50 000 URL в каждом.
Так же Вы можете выбрать удобное количество URL для одного файла самостоятельно.
Фильтр данных – удобный инструмент в процессе создания карты сайта, который позволяет для URL страницы указать поисковым системам такие важные данные: приоритет определенных страниц относительно к другим страницам сайта и режим обновления.
Кроме того, фильтр позволяет исключать в процессе индексации определенные страницы, которые не нужны в файле Sitemap.
Фильтры данных можно применять как к отдельным страницам (для этого нужно ввести URI страницы полностью), так и к группам страниц (для этого нужно ввести фрагмент URL, который соответствует всем подобным страницам. Например: «.jpg» или «/directory/files»).
Лучший способ сообщить о Вашей карте сайта поисковым системам - зарегистрировать сайт в сервисах вебмастеров, которые предоставляют поисковые системы (например: webmaster.yandex.ru у Яндекс или www.google.com/webmasters у Google). После регистрации Вы сможете отправить файлы Sitemap из своего аккаунта.
Другой универсальный способ - в файле robots.txt допишите такую строку:
Sitemap: http://website.tld/mysitemapfile2.xml
Sitemap: http://website.tld/mysitemapfile3.xml
- Войдите в свою учетную запись Google Search Console.
- На боковой панели выберите свой ресурс для того домена, для которого вы хотите отправить файл Sitemap.
- Перейдите к пункту "Файлы Sitemap" в разделе "Индекс" на левой навигационной панели сайта.
- Введите URL-адрес XML-карты сайта в поле "Добавить файл Sitemap" и нажмите "Отправить".
После того как вы отправите новый файл Sitemap, он появится в списке отчета "Обработанные файлы Sitemap" со статусом "Не получено" и пустым "дата последней обработки". Не беспокойтесь об этом, это просто начальный статус, присвоенный Search Console, который означает, что ваш файл ожидает обработки. Через некоторое время (обычно день-два) статус изменится и рядом с ним появится заполненным "дата последней обработки".
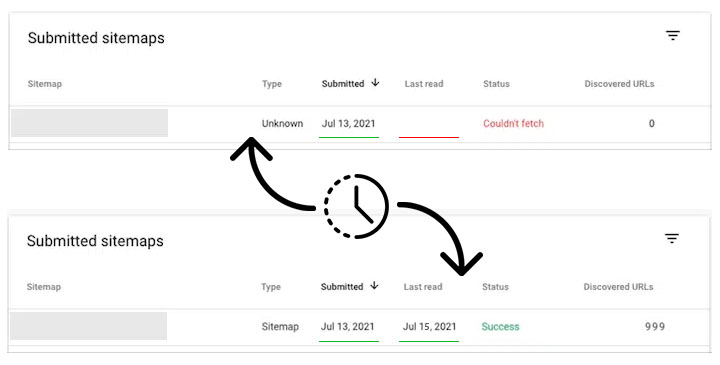
Google не предоставляет определенного времени для завершения процесса. Google использует автоматизированную систему, которая сканирует веб-сайты и обрабатывает определенные документы на основе своих алгоритмов и доступных ресурсов (краулингового бюджета). Поэтому для каждого конкретного сайта это время может оказаться разным. Вы можете отслеживать статус вашего файла Sitemap с помощью отчета о файлах Sitemap, предоставляемого Search Console.
- 1. Войдите в свою учетную запись Bing Webmaster Tools.
- 2. В списке выбора сайтов, который находится сверху в боковом меню, выберите свой веб-сайт, для которого вы хотите отправить файл Sitemap.
- 3. На левой боковой панели нажмите "Карты веб-сайта", а затем кнопку "Отправить карту веб-сайта" вверху.
- 4. Введите URL-адрес XML-карты сайта в текстовое поле и нажмите "Сохранить".
После отправки файла Sitemap вам нужно дождаться его загрузки и обработки Bing.
Bing не предоставляет конкретного времени для завершения процесса. Поэтому для каждого конкретного сайта это время может оказаться разным. Вы можете отслеживать статус своего файла Sitemap с помощью отчета о файлах Sitemap, предоставляемого инструментами Bing Webmaster Tools.
- 1. Войдите в свою учетную запись Яндекс-Вебмастер.
- 2. В верхней части боковой панели выберите свой веб-сайт, для которого вы хотите отправить файл Sitemap.
- 3. На левой боковой панели нажмите "Параметры индексирования", а затем "Файлы Sitemap".
- 4. Введите URL-адрес XML-карты сайта в текстовое поле и нажмите «Добавить».
После того, как вы добавили ваш Sitemap, вам нужно дождаться его загрузки и обработки Яндексом.
Яндекс говорит, что файл Sitemap обычно обрабатывается в течение двух недель после его добавления в Яндекс Вебмастер. Вы можете отслеживать статус своего файла Sitemap с помощью отчета о файлах Sitemap, предоставляемого в Яндекс-Вебмастер.
Не можете найти ответ на нужный вопрос? Мы здесь, чтобы помочь!
Связаться со службой поддержки